万众期待!震惊全网——人人都能上手的最简单的三子棋小游戏来了!
本文共 4254 字,大约阅读时间需要 14 分钟。
文章目录
思维导图
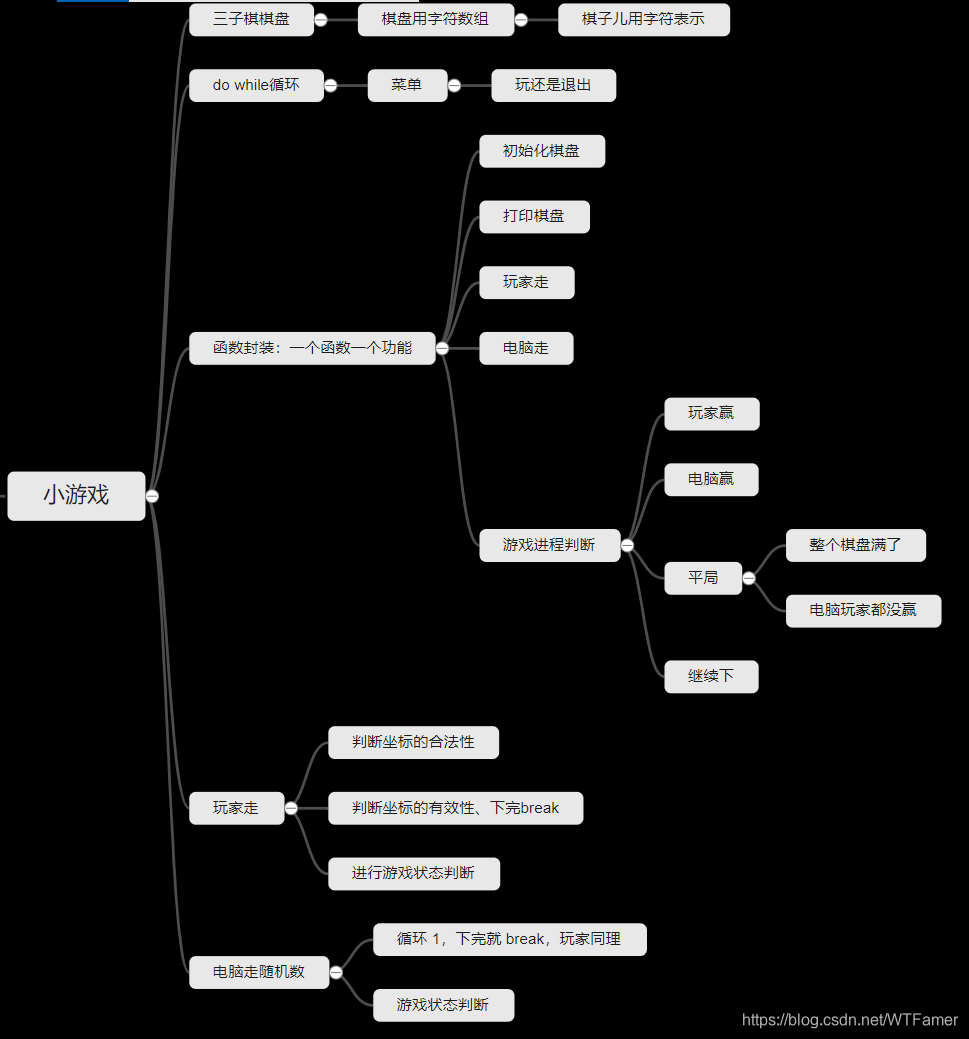
大纲

声明
- 头文件放函数的声明
- .c文件放函数的实现
- 咱们的.c文件放
main函数 - 游戏状态判断 用的 字符,可以自定义
- 玩家的子儿用 *
- 电脑的子儿用 #
- 游戏继续 用 C
- 平局用 Q
棋盘

代码
主函数
int main(){ test(); return 0;} 主函数调用的test函数
void test(){ int input = 0; srand((unsigned int)time(NULL));//从程序开始就生成随机数 do { menu(); printf("请选择:>"); scanf("%d", &input); switch (input) { case 1: game(); break; case 0: printf("退出游戏\n"); break; default: printf("选择错误,请重新选择!\n"); break; } } while (input);} 菜单函数
void menu(){ printf("$$$$$$$$$$$$$$$$$$$$$$$$$$$\n"); printf("---- 1.play 0.exi---\n"); printf("$$$$$$$$$$$$$$$$$$$$$$$$$$$\n");} 游戏Game函数
void game(){ char ret = 0; 数组-存放棋盘的信息。 char board [ROW][COL] = { 0 }; 初始化棋盘,初始化数组。行,列数组传参。 Initboard(board,ROW,COL); 打印棋盘。 Displayboard(board,ROW,COL); 下棋 但凡只要不是继续下的状态就 break,跳出循环。 while (1) { 玩家下棋 Playermove(board, ROW, COL); Displayboard(board, ROW, COL); 判断玩家是否赢 ret=iswin(board, ROW, COL); if (ret != 'C') { break; } 电脑下棋。 computermove(board, ROW, COL); Displayboard(board, ROW, COL); 电脑是否赢 ret=iswin(board, ROW, COL); if (ret != 'C') { break; } } 根据上面的返回 字符 进行判断。 if (ret == '*') { printf("玩家赢\n"); } else if (ret == '#') { printf("电脑赢\n"); } else { printf("平局\n"); }} 游戏Game.h头文件
#define _CRT_SECURE_NO_WARNINGS 1#define ROW 3 方便更换更大的棋盘#define COL 3#include#include #include 函数的声明。初始化棋盘。void Initboard(char board[ROW][COL],int row,int col);打印棋盘void Displayboard(char board[ROW][COL], int row, int col);玩家下棋。void Playermove(char board[ROW][COL], int row, int col);电脑下棋void computermove(char board[ROW][COL], int row, int col);iswin函数玩家赢, 返回 *电脑赢 返回 #平局 返回Q继续 返回 C 要返回这样的字符所以用char类型char iswin(char board[ROW][COL], int row, int col);
游戏Game.c 各种函数的实现
初始化棋盘-
#include"game.h"函数的实现。void Initboard(char board[ROW][COL], int row, int col){ int i = 0; int j = 0; for (i = 0; i < row; i++) { for ( j = 0; j < col; j++) { board[i][j] = ' '; 弄成字符空格 等会儿打印棋盘的时候好看。。 } }} 打印棋盘-
两个控制
- 控制列的 | 最后一列不用打印
- 控制行的 — 最后一行不用打印
- 也就是
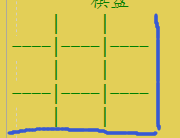
void Displayboard(char board[ROW][COL], int row, int col){ int i = 0; for (i = 0; i < row; i++) 控制打印几行。 { 1,打印一行的数据。 int j = 0; for (j = 0; j < col; j++) { printf(" %c ", board[i][j]); if (j < col - 1) { printf("|"); } } printf("\n"); 2,打印分割行。 if (i < row - 1) { for ( j = 0; j < col; j++) { { printf("---"); if (j < col - 1) 这里打印 | 是为了 和 一行上面的 | 连接起来 { printf("|"); } } } printf("\n"); } }} 玩家走-
void Playermove(char board[ROW][COL], int row, int col){ int x = 0; int y = 0; printf("玩家走:>"); while (1) { printf("请输入要下的坐标"); scanf("%d%d", &x, &y); 进行坐标判断是否合法--路人角度 下标都是 多一的。 if (x >=1 && x<=row && y>=1 &&y<=col) { if (board[x-1][y-1]==' ') { board[x - 1][y - 1] = '*'; break; } else { printf("该坐标被占用"); } } else { printf("坐标输入非法,请重新输入!\n"); } }} 电脑走-
- 随机数的调用
- 下完就break
void computermove(char board[ROW][COL], int row, int col){ int x = 0; int y = 0; printf("电脑走:>\n"); while (1) { x = rand() % row;//生成随机数 y = rand() % col; if (board[x][y] == ' ') { board[x][y] = '#'; break; } }} 游戏状态判断-
- 赢,输,平局,继续
- 谁赢:每行,每列,两个对角线的判断。- 那个坐标是啥字符,就返回啥字符。
- 平局要写一个判断是否棋盘满了的函数 IsFull
- 三种情况都不是就继续下。
返回字符 charchar iswin(char board[ROW][COL], int row, int col){ int i = 0; 行三行 for ( i = 0; i < row; i++) { if (board[i][0] == board[i][1] && board[i][1] == board[i][2] && board[i][1] != ' ') { return board[i][1]; } } 竖三列 for ( i = 0; i < col; i++) { if (board[0][i] == board[1][i] && board[1][i] == board[2][i] && board[1][i] != ' ') { return board[1][i]; } } 两个对角线得判断 if (board[0][0] == board[1][1] && board[1][1] == board[2][2] && board[1][1] != ' ') { return board[1][1]; } if (board[2][0] == board[1][1] && board[1][1] == board[0][2] && board[1][1] != ' ') { return board[1][1]; } 要么平局,要么继续 判断是否平局。发现没有人赢,然后棋盘又满了,说明平局。 if (isfull(board, ROW, COL) == 1) 判断满了就返回1 { return 'Q'; } return 'C';} 棋盘满不满-
int isfull(char board[ROW][COL], int row, int col) //返回1表示棋盘满了。返回0表示棋盘美满。{ int i = 0; int j = 0; for ( i = 0; i < row; i++) { for ( j = 0; j < col; j++) { if (board[i][j]==' ') { return 0;//棋盘没满。 } } } return 1;} 回头看Game函数

游戏画面


GG.
如果感觉海星,请一键三联哦~
转载地址:http://kol.baihongyu.com/
你可能感兴趣的文章
Mysql 常见ALTER TABLE操作
查看>>
MySQL 常见的 9 种优化方法
查看>>
MySQL 常见的开放性问题
查看>>
Mysql 常见错误
查看>>
mysql 常见问题
查看>>
MYSQL 幻读(Phantom Problem)不可重复读
查看>>
mysql 往字段后面加字符串
查看>>
mysql 快照读 幻读_innodb当前读 与 快照读 and rr级别是否真正避免了幻读
查看>>
MySQL 快速创建千万级测试数据
查看>>
mysql 快速自增假数据, 新增假数据,mysql自增假数据
查看>>
MySql 手动执行主从备份
查看>>
Mysql 批量修改四种方式效率对比(一)
查看>>
Mysql 报错 Field 'id' doesn't have a default value
查看>>
MySQL 报错:Duplicate entry 'xxx' for key 'UNIQ_XXXX'
查看>>
Mysql 拼接多个字段作为查询条件查询方法
查看>>
mysql 排序id_mysql如何按特定id排序
查看>>
Mysql 提示:Communication link failure
查看>>
mysql 插入是否成功_PDO mysql:如何知道插入是否成功
查看>>
Mysql 数据库InnoDB存储引擎中主要组件的刷新清理条件:脏页、RedoLog重做日志、Insert Buffer或ChangeBuffer、Undo Log
查看>>
mysql 数据库中 count(*),count(1),count(列名)区别和效率问题
查看>>